


RA3: 더 빠른 강화 학습을 위한 시간적 행동 추상화를 활용한 중간 학습 (RL) 및 코드 LLMs에서의 후속 학습
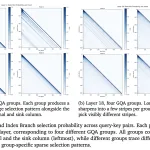
Apple의 새로운 연구는 중간 학습이 강화 학습 후 후속 학습을 하기 전에 무엇을 해야 하는지 공식화하고 RA3 (Reasoning as Action Abstractions)를 소개합니다. RA3는 전문가의 흔적으로부터 시간적으로 일관된 잠재적 행동을 학습하고 그에 대해 미세 조정합니다. 중간 학습은 (1) 최적의 행동 부분 공간으로 가지치기하고 (2) 줄여야 함을 보여줍니다.
2025년 10월 9일 오전 2시 20분