


구글 AI, 차별적인 개인 파티션 선택을 위한 혁신적인 머신러닝 알고리즘 제안
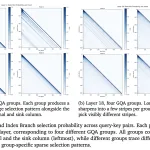
구글 AI팀은 차별적인 개인 파티션 선택을 위한 새로운 머신러닝 알고리즘을 제안했다. 이는 대규모 머신러닝 및 데이터 분석에서 사용자 정보를 보호하는 데 중요한 역할을 한다. 이 알고리즘은 엄격한 개인 정보 보호를 유지하면서 대규모 사용자 기여 데이터셋에서 고유한 항목을 안전하게 추출하는 과정을 포함한다.
2025년 8월 23일 오전 4시 15분