
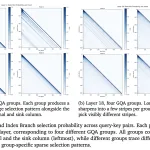



프롬프트 엔지니어링의 기술 습득하기
AI 주도적 세계에서 프롬프트 엔지니어링은 중요한 기술이다. 이는 간단한 질의를 넘어서 모호한 아이디어를 명확하고 실행 가능한 AI 결과물로 변환할 수 있는 능력을 제공한다. ChatGPT 4o, Google Gemini 2.5 플래시, Claude Sonnet 4 등을 사용하는 경우 네 가지 기본 원칙이 전체 잠재력을 발휘하게 한다.
2025년 7월 9일 오전 11시 50분


































































































