


2025년 LLM 서빙을 위한 상위 6개 추론 런타임 비교
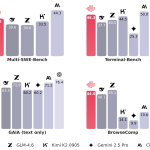
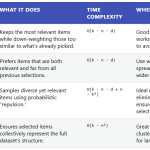
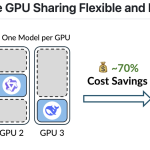
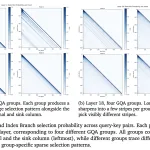
대형 언어 모델은 훈련보다는 실제 트래픽 하에서 토큰을 빠르고 저렴하게 제공하는 방법에 더 많은 제약을 받는다. 이는 런타임이 요청을 일괄 처리하는 방식, 프리필과 디코드를 어떻게 중첩시키는지, KV 캐시를 어떻게 저장하고 재사용하는지에 달려 있다. 서로 다른 엔진들은 서로 다른 절충안을 제공한다.
2025년 11월 7일 오전 5시 12분