
언어 모델은 정말로 얼마나 많은 정보를 기억할까? 메타의 새로운 프레임워크가 비트 레벨에서 모델 용량을 정의합니다
최신 언어 모델은 훈련 데이터를 의미있게 기억하는지에 대한 논란이 있습니다. 메타의 새로운 프레임워크는 모델의 용량을 비트 수준에서 정의하여 이 문제를 다루고 있습니다.
2025년 6월 11일 오전 1시 56분









최신 언어 모델은 훈련 데이터를 의미있게 기억하는지에 대한 논란이 있습니다. 메타의 새로운 프레임워크는 모델의 용량을 비트 수준에서 정의하여 이 문제를 다루고 있습니다.

대규모 언어 모델(Large language models, LLMs)은 많은 AI 기반 서비스를 구동하지만 추론 중의 계산 비용이 큰 과제로 남아있었습니다. 본 논문은 WINA라는 훈련 무료 희소 활성화 프레임워크를 소개하며, 계산 효율성과 출력 품질의 균형을 최적화하는 것이 중요한 연구 분야임을 강조합니다.

이 AI 논문은 웹 네비게이션 에이전트를 구축하는 복잡성과 사용자 목표 해석, 웹사이트 구조 이해, 다단계 결정 등의 작업을 필요로 하는 것에 초점을 맞추고 있다.
이 연구는 대규모 언어 모델의 추론 능력을 향상시키는 긴 사고 체인이 시간 효율성 및 첫 번째 토큰 도달 시간에 미치는 영향을 분석하고, 강화 학습을 활용하여 다중 단계 질문에 대한 간헐적 추론을 유도하는 새로운 학습 패러다임을 제안한다. 모델이 간헐적 추론을 수행할 수 있는 능력을 강화하기 위해 간단하면서도 효과적인 규칙 기반 보상 시스템을 도입한다.
복잡한 데이터 기반 작업을 처리하는데 강력한 도구인 신경망은 종종 차량 라우팅이나 작업 일정 등 엄격한 제약 하에서 이산적인 결정을 내리는 데 어려움을 겪습니다. 이러한 문제들을 해결하기 위해 연구된 새로운 AI 프레임워크인 Differentiable MCMC 레이어를 소개한 논문입니다.
Magentic-UI는 복잡한 웹 작업을 처리하고 다단계 계획과 브라우저 사용이 필요한 작업을 사람들과 협력하여 완료하는 오픈 소스 에이전트 프로토타입이다.
Anthropic이 새로운 언어 모델인 클로드 오퍼스 4와 클로드 소넷 4를 출시했다. 이 업데이트는 클로드 모델 패밀리의 기술적 세련성을 대폭 향상시켰는데, 특히 구조화된 추론, 소프트웨어 엔지니어링 및 자율 에이전트 행동과 관련된 영역에서 주목할만한 발전을 이루었다.
대규모 언어 모델의 규모가 급격하게 증가함에 따라 여러 컴퓨팅 유닛 간의 효율적인 분산 추론이 점점 중요해지고 있다. 그러나 텐서 병렬성과 같은 인기 있는 분산 추론 기술로 인한 통신 오버헤드는 확장성과 낮은 지연 시간을 달성하는데 중요한 도전 요소이다. 따라서 통신 오버헤드를 줄이기 위해 주의도를 기울여 동기화를 선택적으로 제거하는 싱크포인트 드롭(SPD) 최적화 기술을 소개하고 있다.

기존 생성 모델은 대규모 고품질 데이터셋에 의존하는데, Meta AI가 발표한 역순 샘플링 기술은 이를 극복하고 데이터 부족 상황에서도 보상 주도적 생성 모델링을 가능하게 합니다.
조지아텍과 스탠포드 대학 연구진이 MLE 작업의 자동화를 탐구하고, AI 에이전트를 활용하여 엔드 투 엔드 워크플로우를 효율적으로 조율하는 데 어려움을 겪는 과제를 처리하는 것을 연구했다.
기계 학습 시스템이 추천 엔진부터 자율 시스템까지 다양한 응용 프로그램에서 중요해지면서, 이러한 시스템들의 환경 지속 가능성에 대한 필요성이 증가하고 있습니다. CATransformers는 AI 모델과 하드웨어를 지속 가능한 엣지 배포를 위해 공동 최적화하는 탄소 인식 기계 학습 프레임워크입니다.
시퀀스 모델은 언어, 시계열, 신호와 같은 시간 구조 데이터를 처리하기 위해 설계되었으며, 내부적으로 시간 관계를 관리하여 일관된 출력을 생성함. 이 AI 논문은 시퀀스 모델의 메모리 활용을 측정하는 효과적인 상태 크기(ESS) 메트릭을 제시하며 성능 최적화에 도움을 줌.

대규모 추론 모델(LRMs)은 수학, 코딩, 과학적 추론에서 놀라운 능력을 보여주지만, 내부 지식에만 의존할 때 복잡한 정보 연구 요구를 해결하는 데 제약이 있습니다. WebThinker는 이러한 한계를 극복하고 다단계 추론 과정을 통해 정확한 과학 보고서를 생성하는데 도움을 줍니다.

최근 LLMs의 발전으로 자연어 이해, 추론 및 생성이 크게 향상되었지만, 이 모델들은 종종 환각을 생성하는데, 이는 신뢰성을 저해함. 높은 위험도메인에서 특히 시급하게 대응이 필요함.
구글 연구진은 AMIE가 다중모달 추론을 사용하여 원격 진료에서 텍스트 이외의 이미지, 검사 결과 등을 고려해 주치의를 능가할 수 있는 능력을 갖추었다.
MIT의 연구진이 신규 유형의 “상태-공간 모델”을 개발했는데, 이는 조화진동자의 원리를 활용했다. 이 모델은 뇌의 신경 역학에서 영감을 받아 개발되었으며, 인공지능 및 머신러닝 분야에 혁신을 가져올 것으로 예상된다.
미분적으로 개인 정보 보호(DP) 최적화 알고리즘을 연구하고 부드럽지도 볼록하지도 않은 확률적 및 경험적 목적 함수에 대해 제안되며, 기존 작업을 개선하는 샘플 복잡도 한계를 가진 방법을 제안합니다.
이 연구는 확산 모델에서의 구성에 대한 이론적 기초를 연구하며, 특히 분포의 조합을 통한 외삽과 길이 일반화에 초점을 맞추고 있습니다. 이전 연구에서는 선형 점수 조합을 통해 분포를 조합하면 길이 일반화를 달성할 수 있다는 것이 밝혀졌으나, 이러한 조합이 왜 동작하는지에 대한 이론적 이해는 아직 미완성 상태입니다. 이 논문은 이러한 기본적인 공백을 다루기 시작합니다.
연합 텔레메트리 응용프로그램을 고려하여, 지역 Pan-개인정보 보호에 대한 연구를 진행하고, 연합 시스템에서 이벤트 발생 횟수를 모니터링할 때 지역 장치에서의 이벤트 발생은 심지어 해당 장치의 침입자에게도 숨겨져야 함을 보여줌.
대형 언어 모델(LLM)은 수학, 논리, 기획, 코딩 등의 추론 작업에서 상당한 주목을 받았다. 그러나 이러한 모델을 실제 상황에 적용할 때 중요한 도전 과제가 발생한다. 현재의 구현은 대부분 필요한 모든 정보가 명확하게 제공된다는 가정 하에 작동하지만, 현실은 종종 불완전하거나 모호한 상황을 제시한다.
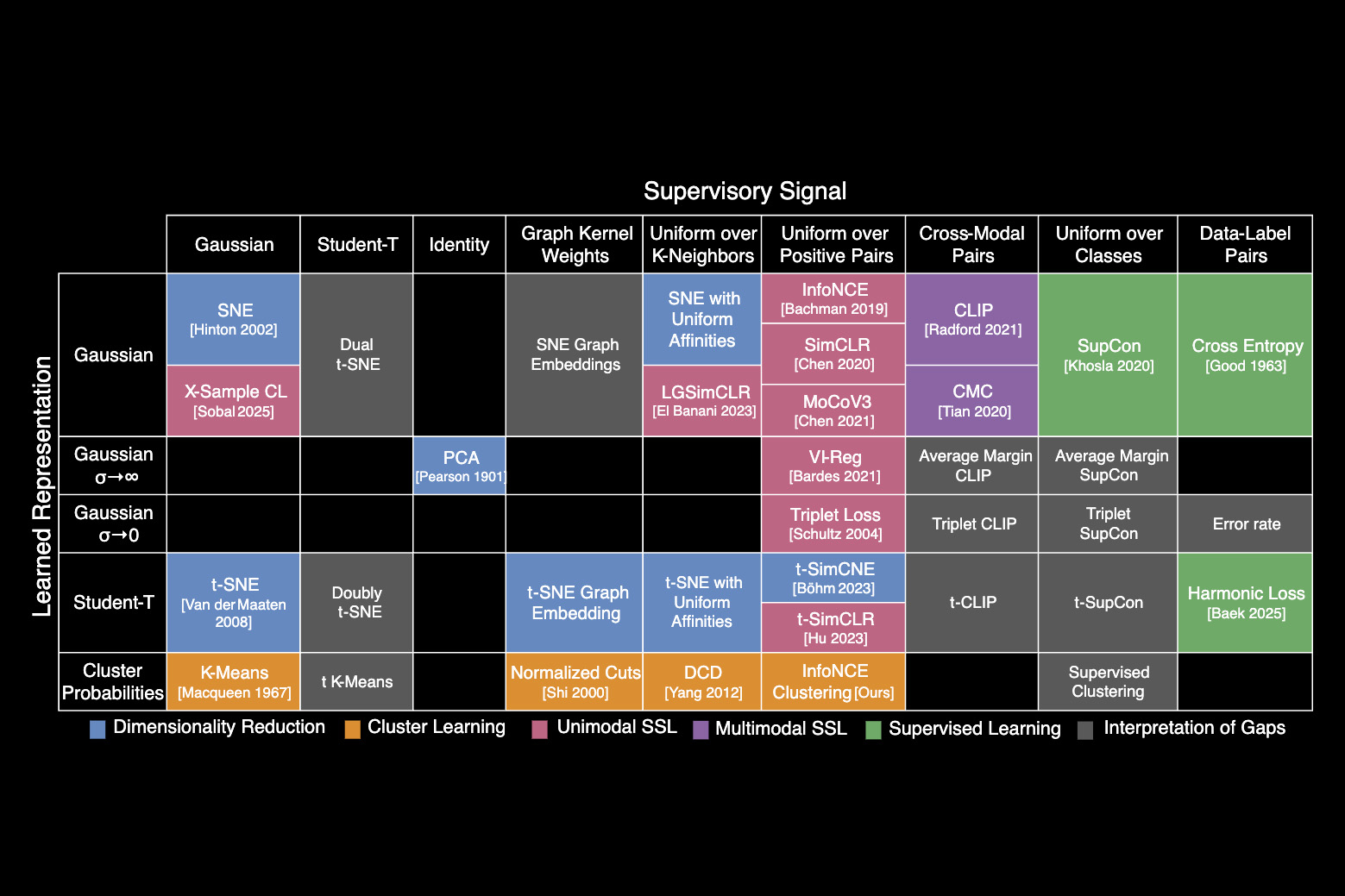
연구자들이 AI 모델을 개선하거나 새로운 모델을 만드는데 도움이 되는 통합 프레임워크를 만들었다.
레이블이 없는 데이터로부터 분리된 표현을 학습하는 것은 기계 학습에서의 중요한 과제이다. 이를 해결함으로써 일반화, 해석 가능성 또는 공정성과 같은 다른 문제들을 해결할 수 있다. 이론적으로 해결하기 어렵지만, 실제로는 이전 일치를 통해 분리가 종종 이루어진다. 또한, 최근 연구들은 기하학적 고려사항을 활용하여 이전 일치 접근법을 개선할 수 있음을 보여주었다.
본 논문은 머신러닝을 위한 확산 모델 및 흐름 일치 수학에 대한 접근 가능한 초급 과정을 제시한다. 확산을 가능한 간단하게 가르치고 있으며, 수학적이고 머신러닝에 대한 선행 지식은 최소화했지만, 올바름에 대해 논의할만한 충분한 기술적 세부 정보를 제공한다. 대부분의 튜토리얼과는 달리, Variational Auto Encoder(VAE)나 Stochastic Differential Equations(SDE) 접근 방식을 취하지 않는다. 사실, 핵심 아이디어에는 SDE, ELBO, Langevin dynamics, 심지어 점수 개념이 필요하지 않다. 독자는 단순히…
DART는 Markov 프로세스 노이즈 제거를 통해 훈련되는 확산 모델의 한계를 극복하기 위해 제안된 transformer 기반 모델로, 비-Markovian 프레임워크 내에서 자기 회귀와 확산을 통합한다. 이미지 패치를 공간적, 스펙트럼적으로 반복적으로 노이즈 제거하며 텍스트에서 이미지를 생성한다.
대규모 언어 모델의 선호도 조정을 위해 DPO가 널리 사용되고 있지만 토큰 간 중요도 차이를 무시하여 최적화 효율성에 영향을 줄 수 있음. 이에 TIS-DPO를 제안하여 토큰 간 중요도를 고려한 최적 데이터를 제시함.
이 논문은 ICLR 2025의 Foundation Models in the Wild 워크샵에서 받아들여졌다. 이미지의 시각적 이해는 본질적으로 맥락에 의존적이며, 이미지에서 주목하는 대상은 주어진 작업에 따라 달라진다. 대부분의 기존 이미지 인코딩 패러다임은 이미지를 고정된 범용 특징 벡터로 표현하는데, 다양한 시각 정보를 우선순위에 따라 다르게 처리하는 잠재적 필요성을 간과한다.
연구진은 두 가지 인기 있는 방법을 결합하여 에너지를 적게 사용하고 노트북이나 스마트폰에서 로컬로 실행할 수 있는 이미지 생성기를 만들었다.

MIT에서 EECS와 철학 교수들이 공동으로 진행하는 새로운 강좌에서 학생들은 디지털 시대의 도덕적 딜레마에 대해 다룹니다.
머신러닝 모델을 사용하여 신경과학자들이 청각 처리가 현실 세계 청력에 미치는 영향을 연구할 수 있게 되었습니다.

NeuroTrALE 소프트웨어 도구는 대량의 뇌 이미징 데이터를 빠르고 효율적으로 반 자동으로 처리하는 데 도움을 준다.

NeurIPS는 인공지능 및 머신러닝 분야에서 세계 최대 규모의 학회로, 딥마인드는 다이아몬드 후원사로 참여하여 인공지능 및 머신러닝 커뮤니티에서의 연구 진전 교류를 돕고 있다. 딥마인드 팀은 35개의 외부 협업을 포함한 47편의 논문을 가상 패널과 포스터 세션을 통해 발표할 예정이다.