


LLM 에이전트를 위한 이 에이전틱 메모리 연구가 장기 및 단기 기억을 통합하는 방법
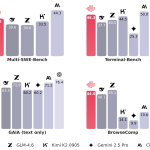
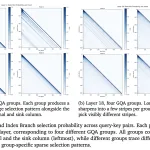
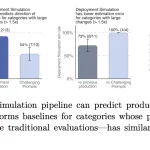
이 연구는 LLM 에이전트를 위해 장기 기억에 저장할 내용, 단기 기억에 유지할 내용, 버릴 내용을 스스로 결정하는 방법을 설계하는 방법에 대해 다루고 있습니다. 이 연구에서는 텍스트 생성과 동일한 액션 공간을 통해 두 유형의 기억을 관리하는 단일 정책을 학습할 수 있는지에 대해 탐구하고 있습니다.
2026년 1월 13일 오전 2시 05분