


로봇을 위한 MEM 공개: 복잡한 작업을 위한 3-4B VLAs에 15분간의 컨텍스트를 제공하는 멀티 스케일 메모리 시스템
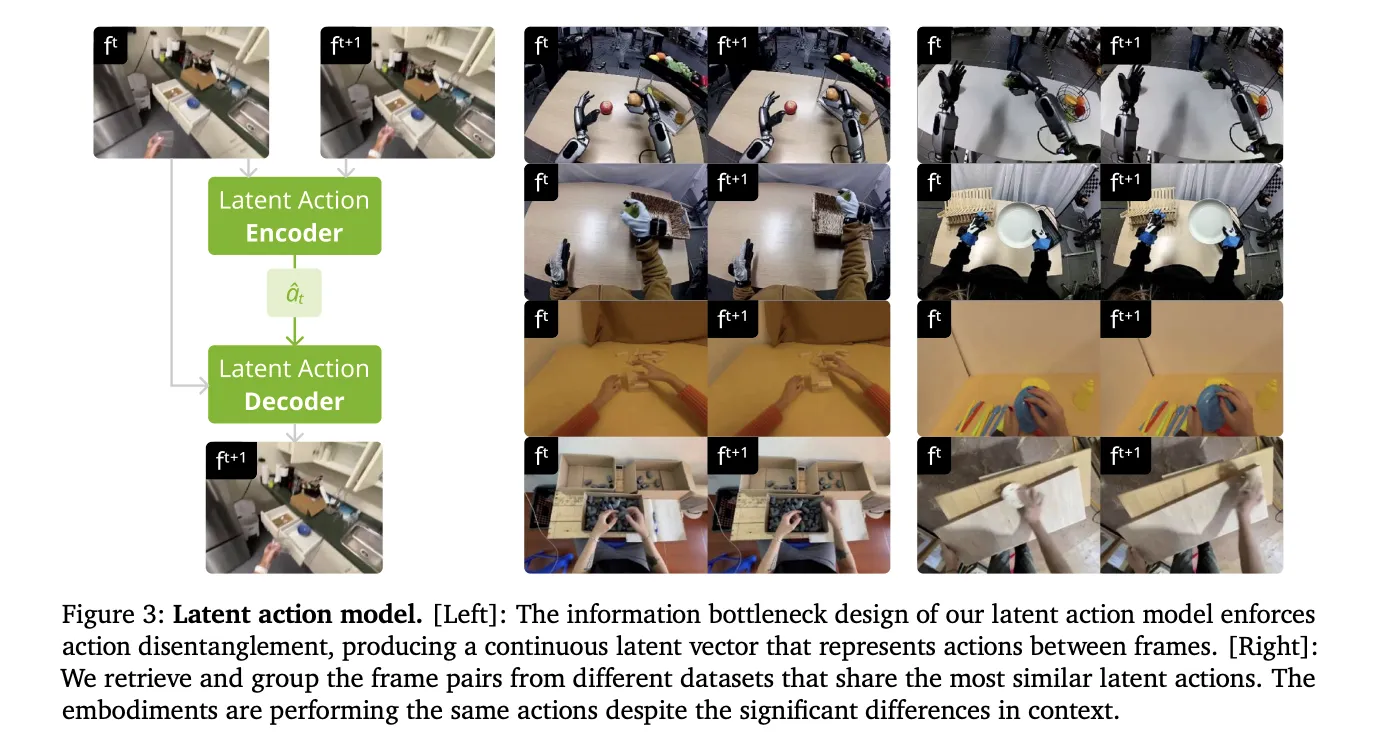
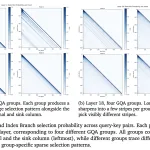
현재의 로봇 정책은 주로 한 번의 관찰 또는 매우 짧은 역사에 기반하며, 장기 과제에 부족함이 있습니다. 이를 해결하기 위해 Physical Intelligence, Stanford, UC Berkeley, MIT의 연구진이 개발한 멀티 스케일 메모리 시스템은 복잡한 작업에 필요한 15분간의 컨텍스트를 제공합니다.
2026년 3월 4일 오전 1시 01분