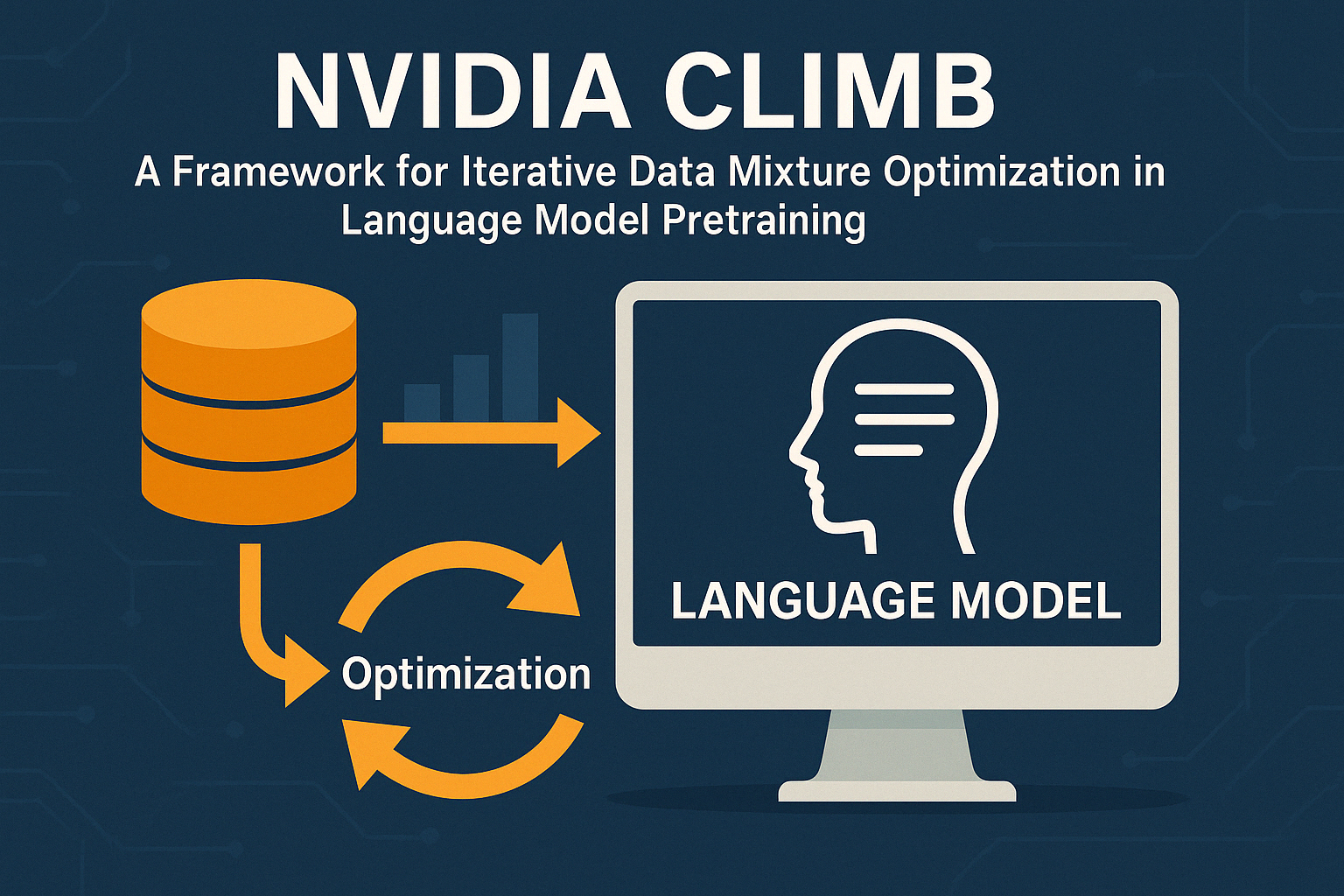





규모의 감독은 보장되지 않습니다: MIT 연구진, 새로운 Elo 기반 프레임워크로 중첩 AI 감독의 취약성 측정
인공 일반 지능(AGI)으로 나아가는 최첨단 AI 기업들은 강력한 시스템이 조절 가능하고 유익하게 유지되도록 보장하는 기술이 필요하다. 이에 대한 주요 접근 방식은 Recursive Reward Modeling, Iterated Amplification 및 Scalable Oversight와 같은 방법을 포함한다. 이들은 약한 시스템이 강력한 시스템을 효과적으로 감독할 수 있도록 하는 것을 목표로 한다.
2025년 5월 3일 오후 3시 44분