세일즈포스 코드젠 튜토리얼: 유닛 테스트와 안전 점검을 통한 파이썬 함수 생성 및 검증
세일즈포스 코드젠을 활용한 엔드 투 엔드 워크플로우를 구현하는 방법을 소개합니다. 함수 추출, 구문 검사, 정적 안전 점검, 유닛 테스트 검증 등을 포함합니다.
2026년 6월 18일 오후 10시 44분



세일즈포스 코드젠을 활용한 엔드 투 엔드 워크플로우를 구현하는 방법을 소개합니다. 함수 추출, 구문 검사, 정적 안전 점검, 유닛 테스트 검증 등을 포함합니다.
퍼플렉시티가 자가 개선 메모리 시스템인 ‘브레인’을 출시했습니다. 이 시스템은 에이전트의 작업을 기억하며, 성과와 실패를 분석해 개선합니다.

KV 캐시가 긴 컨텍스트에서 모델 가중치를 초과하는 상황에서 TurboQuant, OSCAR, EpiCache가 메모리 병목 현상을 해결하기 위해 각기 다른 접근 방식을 취하고 있습니다. 이들은 경쟁보다는 상호 보완적인 관계에 있습니다.
OpenAI가 생명과학 연구를 평가하는 750개 작업으로 구성된 LifeSciBench를 발표했습니다. 이 벤치마크는 173명의 박사 과학자들이 작성한 기준을 바탕으로 AI 모델의 추론과 결정을 평가합니다.
이 튜토리얼에서는 NVIDIA SkillSpector를 사용하여 배포 전 AI 기술의 보안 위험을 평가하는 방법을 소개합니다. 양호한 기술과 의도적으로 취약한 기술을 구축하고, SkillSpector의 LangGraph 워크플로우를 통해 스캔합니다.
Vercel이 Apache-2.0 라이선스의 오픈소스 AI 에이전트 프레임워크 ‘Eve’를 공개했다. 각 에이전트는 기능에 맞춰 파일 디렉토리로 구성되어 있다.
MiniMax가 새로운 희소 주의 메커니즘인 MSA를 발표했습니다. 이 기술은 쿼리당 상위 k 개의 키-값 블록을 선택하여 계산량을 28.4배 줄이는 데 성공했습니다.
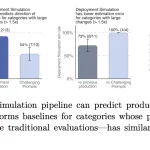
OpenAI가 2026년 6월 16일 배포 시뮬레이션을 도입했습니다. 이 방법은 새로운 모델 출시 전 과거 대화를 재생하여 배포 시 원치 않는 행동의 비율을 추정합니다.
xFormers를 이용해 메모리 효율적인 트랜스포머 모델을 구축하는 방법을 소개합니다. GPU에서 빠르고 효율적인 모델을 구현하며, 다양한 기술적 요소를 검토합니다.
Qwen 팀의 새로운 Qwen-RobotSuite는 조작, 비디오 세계 모델링, 내비게이션을 위한 세 가지 AI 모델을 포함합니다. 각 모델의 구조와 데이터 파이프라인, 벤치마크 결과를 살펴봅니다.
헤르메스 에이전트가 비동기 서브 에이전트를 도입하여 위임된 작업이 부모 채팅을 차단하지 않도록 개선했습니다. 새로운 도구 세트를 통해 작업을 생성하고 관리하는 방법을 소개합니다.
‘Meet Atoms’는 개발자나 소프트웨어 엔지니어가 아니더라도 아이디어를 AI에게 설명하면 앱을 구축하고 배포할 수 있는 노코드 도구입니다.
구글 클라우드가 AI 에이전트를 위한 개방형 지식 포맷(OKF)을 소개했습니다. 이 포맷은 마크다운 파일과 YAML 프론트매터로 구성된 디렉토리를 통해 AI에 필요한 맥락을 제공합니다.
이 튜토리얼에서는 Docling Parse를 사용하여 PDF 문서를 구조적으로 분석하는 워크플로우를 구축하는 방법을 소개합니다. Python 환경 설정부터 PDF 생성, 데이터 추출까지의 과정을 다룹니다.
사카나 AI의 첫 상용 제품인 사카나 마를린은 최대 8시간 동안 자율적으로 작동하며, AB-MCTS와 AI 과학자 워크플로우를 기반으로 다수의 페이지로 구성된 보고서와 슬라이드를 생성합니다.
Flash-KMeans는 Triton GPU 커널을 활용한 오픈소스 IO 인식 K-평균 구현체로, 기존의 수학적 접근을 변경하지 않고도 FAISS보다 200배 빠른 성능을 자랑합니다.
Z.ai가 2026년 6월 13일 GLM-5.2를 출시했습니다. 이 모델은 100만 토큰의 컨텍스트 창을 제공하며, 높은 노력과 최대 노력 수준을 지원합니다. 출시 시점에는 벤치마크가 제공되지 않았습니다.
클로드 코드는 단일 채팅 프롬프트가 아닌 계층적 에이전트 코딩 도구입니다. 이 가이드는 25가지 기능을 설명하며, 비교표와 코드 예제, 실제 사용 사례, 인터랙티브 데모를 포함하고 있습니다.
이번 튜토리얼에서는 FineWeb 데이터셋을 활용한 고급 실습 과정을 소개합니다. 전체 데이터셋을 다운로드하지 않고도 샘플을 스트리밍하며, 주요 필드를 분석합니다.
다트브릭스가 코딩 에이전트인 클로드 코드, 코덱스, 파이 위에서 작동하는 메타 하네스 ‘옴니젠트’를 오픈 소스로 공개했습니다. 이 프로젝트는 구성, 정책 관리, 실시간 세션 공유 기능을 제공합니다.
이 튜토리얼에서는 QwenPaw 작업공간을 구축하고 테스트하는 방법을 소개합니다. 인증 설정, 모델 제공자 연결, 맞춤형 기술 및 로컬 지식 파일을 포함한 구조화된 작업공간을 만드는 과정을 다룹니다.
앤트로픽이 미국 정부의 수출 통제 지침에 따라 클로드 파블 5와 미토스 5 모델을 비활성화했습니다. 다른 모델인 오푸스 4.8은 여전히 사용 가능합니다.
Moonshot AI가 Kimi K2.7-Code를 오픈소스로 공개했다. 이 모델은 Kimi K2.6을 기반으로 하며, Kimi Code Bench v2에서 +21.8%의 성능 향상을 기록했다.
city2graph, OSMnx, PyTorch Geometric을 활용하여 도시 POI와 거리 네트워크 데이터를 수집하고, 공간 그래프를 구성하여 POI 카테고리를 예측하는 방법을 제시합니다.

구글이 Gemini 3.1 Pro 기반의 텍스트-투-SQL 기능인 Gemini-SQL2를 발표하며 BIRD 단일 모델 리더보드에서 80.04%의 실행 정확도를 기록했습니다. 이 점수의 의미와 리더보드의 구성에 대해 살펴봅니다.
문샷 AI가 macOS와 Windows에서 사용할 수 있는 로컬 데스크탑 에이전트 Kimi Work를 출시했습니다. 이 에이전트는 300개의 서브 에이전트로 구성된 스웜을 운영하며, 웹 브라우저를 제어하고 백그라운드 작업을 예약합니다.

Zyphra가 1.2B, 2.7B, 7B 파라미터를 가진 Zamba2-VL 비전-언어 모델을 출시했습니다. 이 모델은 Mamba2와 Transformer를 결합하여 첫 번째 토큰 생성 시간을 대폭 단축합니다.
이 튜토리얼에서는 MONAI를 사용하여 Medical Segmentation Decathlon Task09 데이터셋의 3D 비장 분할 파이프라인을 구축하는 방법을 소개합니다. CT 스캔을 활용한 다양한 의료 영상 변환 기법을 적용합니다.
퍼플렉시티가 딥 리서치를 컴퓨터 내에서 운영하며, 복잡한 질문을 하위 작업으로 나누고 20개 이상의 최전선 모델을 통해 연구를 분배합니다.
xAI가 Grok Build의 인-터미널 마켓플레이스를 출시했습니다. 이 마켓플레이스는 MongoDB, Vercel, Sentry, Chrome DevTools, Cloudflare, Superpowers 플러그인을 포함하고 있습니다.
누스 리서치가 허메스 에이전트 대시보드를 통해 사용자들이 여러 단계를 거치지 않고도 완전한 에이전트 프로필을 구축할 수 있도록 지원합니다.
코헤어가 첫 번째 개발자 코딩 모델인 ‘노스 미니 코드’를 발표했습니다. 이 모델은 30B 혼합 전문가로 구성되어 있으며, 단일 H100에서 256K의 컨텍스트 길이를 지원합니다.
Microsoft SkillOpt의 전체 워크플로우를 구현하여 최적화 루프를 실행하고, 진화된 기술을 기준 기술과 비교하는 과정을 다룹니다.

구글 딥마인드가 260억 개의 매개변수를 가진 DiffusionGemma 모델을 공개했습니다. 이 모델은 텍스트 확산 기술을 활용하여 GPU에서 최대 4배 빠른 생성 속도를 자랑합니다.
소프트웨어 개발 환경이 변화하고 있습니다. 엔지니어들은 이제 대부분의 코드를 손으로 입력하지 않고, AI 에이전트가 작업을 수행합니다. 이 가이드는 2026년의 주요 AI 코딩 에이전트와 개발 플랫폼을 소개합니다.
앤트로픽이 클로드 파블 5를 일반 사용자에게 제공하고, 클로드 미토스 5는 사이버 안전 장치가 해제된 상태로 제한적으로 출시했습니다. 두 모델은 동일한 기본 모델을 기반으로 하지만, 서로 다른 안전 장치를 갖추고 있습니다.
이 튜토리얼에서는 NVIDIA의 Nemotron-Pretraining-Code-v3 데이터셋을 활용하여 코드 프리트레이닝 연구를 위한 대규모 메타데이터 인덱스를 구축하는 방법을 소개합니다. 스트리밍 방식으로 데이터셋을 처리하고, 언어, 파일 확장자, 저장소 빈도 등을 분석합니다.
구글이 Gemini 3.5 라이브 번역 서비스를 출시했다. 이 서비스는 70개 이상의 언어로 음성 간 번역을 실시간으로 제공하며, 구글 미트와 번역 앱을 통해 이용할 수 있다.
이 튜토리얼에서는 NVIDIA cuTile Python을 활용하여 Colab 환경에서 벡터 추가, 행렬 추가 및 행렬 곱셈을 위한 타일 기반 GPU 커널을 구축하는 방법을 설명합니다.

하버드와 퍼플렉시티의 새로운 연구에 따르면, AI 에이전트는 세션당 26분의 자율 작업을 수행하는 반면, 검색 보조자는 33초에 불과한 것으로 나타났다. 이는 자율성, 시간, 비용에서 큰 이점을 보여준다.
이 튜토리얼에서는 ClawHub 보안 신호 데이터셋을 활용해 AI 기술을 평가하는 스캐너의 분석 방법을 살펴봅니다. 데이터 로딩, 판별 결과 및 심각도 레이블을 점검하고, 다양한 분석 도구의 결과를 비교합니다.
샤오미의 MiMo 팀이 TileRT와 함께 MiMo-V2.5-Pro-UltraSpeed를 출시했습니다. 이 모델은 단일 8-GPU 노드에서 1조 매개변수를 활용해 초당 1000개 이상의 토큰을 디코딩할 수 있습니다.
마이크로소프트 AI가 MAI-Transcribe-1.5를 출시했습니다. 이 모델은 43개 언어를 지원하며, 특정 도메인 용어에 대한 키워드 편향을 추가하고, 인공지능 분석 리더보드에서 2.4%의 단어 오류율을 기록했습니다. 또한, 1시간 분량의 오디오를 15초 이내에 전사할 수 있습니다.
구글 리서치가 제미니 엔터프라이즈 에이전트 플랫폼에 에이전틱 RAG 프레임워크를 도입했습니다. 이 시스템은 다중 소스 쿼리에 대한 충분한 맥락을 확보할 때까지 재검색을 수행하여 정확도를 높입니다.
로우코드 및 노코드 AI 플랫폼은 프롬프트를 사용해 작동하는 앱, 에이전트 또는 모델로 변환합니다. 이 가이드는 21개의 도구를 비교하며, 각 도구의 공식 사이트 링크도 포함되어 있습니다.

UIUC와 Chroma가 개발한 Harness-1은 20억 매개변수로 구성된 검색 서브 에이전트로, 강화 학습을 통해 훈련되었습니다. 이 시스템은 검색과 검증을 효율적으로 관리합니다.
이 튜토리얼에서는 NVIDIA garak을 사용하여 방어적 LLM 레드팀 워크플로우를 구축하는 방법을 안내합니다. 설정, 플러그인 탐색, 실제 모델 스캔 등을 포함한 전체 과정이 설명됩니다.
이 튜토리얼에서는 GEPA를 사용하여 소규모 언어 모델이 다단계 산술 문제를 해결하는 방식을 개선하는 방법을 소개합니다. 약한 초기 프롬프트에서 시작해 구조화된 평가자를 통해 실행 가능한 피드백을 제공합니다.
구글이 Colab CLI를 출시하여 개발자와 AI 에이전트가 로컬 코드를 원격 Colab GPU 및 TPU 환경에서 실행할 수 있게 되었습니다.

문샷 AI가 TypeScript로 작성된 오픈소스 터미널 코딩 에이전트 Kimi Code CLI를 출시했습니다. 이 에이전트는 서브 에이전트와 MCP 구성 기능을 갖추고 있습니다.

NVIDIA가 600M 매개변수를 가진 캐시 인식 스트리밍 모델인 Nemotron 3.5 ASR을 출시했습니다. 이 모델은 하나의 체크포인트에서 40개 언어를 실시간으로 전사할 수 있습니다.
퀄컴 AI 허브 모델을 설정하여 MobileNet-V2 추론과 YOLOv7 탐지를 실행하고 실제 장치에서 모델을 컴파일하는 방법을 배워보세요.
구글 딥마인드가 젬마 4의 QAT 체크포인트 Q4_0과 새로운 모바일 포맷을 발표했습니다. 이 포맷은 장치 메모리를 절약할 수 있는 특징이 있습니다.

NVIDIA가 CRIU 및 cuda-checkpoint 도구를 사용하여 Kubernetes에서 vLLM 추론 작업자를 체크포인트하고 복원하는 ‘다이나모 스냅샷’을 발표했습니다.
퍼플렉시티 AI가 개인용 컴퓨터를 위한 하이브리드 로컬-서버 추론 오케스트레이터를 발표했다. 이 시스템은 AI 작업을 자동으로 온디바이스와 클라우드 모델 간에 라우팅한다.
Microsoft Fara를 Google Colab에서 실행하는 방법을 안내하는 튜토리얼입니다. 이 가이드는 모의 OpenAI 호환 엔드포인트를 사용하여 브라우저 에이전트 루프를 테스트하는 내용을 포함하고 있습니다.
2026년을 맞아 개발자들이 앱을 구축하는 방식을 변화시키고 있는 15개의 바이브 코딩 도구를 소개합니다. 각 도구의 가격과 기능을 비교하여 최적의 선택을 도와드립니다.
이 튜토리얼에서는 ResearchMath-14k 데이터셋을 사용하여 연구 수준의 수학을 위한 NLP 파이프라인을 소개합니다. TF-IDF를 통해 특정 분야의 키워드를 추출하고, 문장 임베딩을 생성하며, 문제의 경향을 시각화합니다.

NVIDIA가 550B의 오픈 Mixture-of-Experts 하이브리드 모델인 Nemotron 3 Ultra를 출시했습니다. 이 모델은 1M 토큰 컨텍스트를 지원하며, 유사한 LLM보다 최대 6배 높은 추론 처리량을 자랑합니다.

Miso Labs가 오픈 웨이트를 기반으로 한 8B 텍스트 음성 변환 모델 MisoTTS를 출시했습니다. 이 모델은 텍스트와 오디오 맥락을 기반으로 화자의 톤에 맞춰 반응합니다.

스탠포드 연구진이 개인 AI 시스템을 위한 오픈소스 프레임워크 OpenJarvis를 공개했습니다. 이 프레임워크는 모든 기능을 기기 내에서 수행하며, 클라우드 모델보다 훨씬 저렴한 비용으로 운영됩니다.
iii를 활용하여 모듈형 함수를 등록하고 여러 트리거에서 재사용하는 방식으로 문서 인텔리전스 백엔드를 구축하는 방법을 소개합니다.
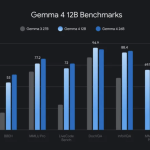
구글 딥마인드가 비전과 오디오를 직접 LLM 백본에 연결하는 인코더 없는 멀티모달 모델 ‘Gemma 4 12B’를 발표했다. 이 모델은 Apache 2.0 라이선스 하에 로컬에서 실행된다.
Nous Research가 Hermes Agent v0.15.2를 위한 크로스 플랫폼 GUI인 Hermes Desktop을 출시했습니다. 이 소프트웨어는 단일 에이전트 코어와 메모리를 공유합니다.

NVIDIA가 물리적 AI를 위한 자율 회귀 VLM 추론기와 확산 생성기를 결합한 오픈 옴니모달 세계 모델인 Cosmos 3를 출시했다.
이 튜토리얼에서는 QLoRA와 DPO를 사용하여 LFM2 모델을 미세 조정하는 방법을 배울 수 있습니다. 구글 코랩에서 TRL과 PEFT를 활용한 과정을 안내합니다.

타이니피시가 ‘빅셋’이라는 오픈소스 다중 에이전트 시스템을 출시했습니다. 사용자가 데이터셋을 한 문장으로 설명하면, 빅셋의 조정자와 하위 에이전트가 실시간 웹을 검색해 구조화된 테이블을 반환합니다.

알리바바의 Qwen 팀이 Bailian 플랫폼에서 Qwen3.7-Plus를 출시했습니다. 이 모델은 이미지와 비디오를 이해하며, 자가 프로그래밍 및 도구 호출 기능을 추가했습니다.
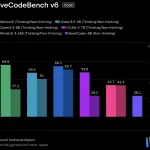
JetBrains가 AI 워크플로우를 위해 10.6조 개의 토큰으로 훈련된 12B MoE 모델인 Mellum2를 Apache 2.0 라이선스 하에 출시했다.
NVIDIA Apex를 소스에서 빌드하고, FusedAdam, FusedLayerNorm, torch.amp의 성능을 벤치마킹하여 트랜스포머 훈련 속도를 높이는 방법을 소개합니다.
MiniMax가 새로운 M3 모델을 출시했습니다. 이 모델은 1M-토큰 컨텍스트 창과 함께 이미지, 비디오, 컴퓨터 사용을 지원하는 기능을 갖추고 있습니다.
메모리 OS는 헬메스 에이전트 위에 구축된 6계층의 오픈소스 프로젝트로, 로컬 지속 메모리를 추가하고 게이트드 검색 및 위키 기능을 제공합니다.

파랄락스는 LLA의 쿼리별 솔버를 학습된 프로젝터로 대체하여 산술 강도를 두 배로 늘리고, 0.6B 및 1.7B에서 혼란도를 개선합니다.
이 튜토리얼에서는 마이크로소프트의 에이전트 거버넌스 툴킷을 활용하여 AI 에이전트의 안전한 워크플로우를 구축하는 방법을 설명합니다. 에이전트의 모든 행동은 거버넌스 레이어를 통해 검증됩니다.
이번 튜토리얼에서는 Python을 위한 강력하고 유연한 로깅 라이브러리인 Loguru를 사용하여 실용적인 사례를 구현합니다.
Trajectory가 UC 버클리 스카이랩 및 Anyscale과 협력하여 지속 학습을 위한 동시 다중 LoRA 훈련 스택을 개발했습니다. 이 시스템은 각 RL 실험을 전용 LoRA 어댑터에 매핑하여 실험 처리량을 2.81배 향상시켰습니다.
이 튜토리얼에서는 SkillNet을 활용하여 재사용 가능한 AI 스킬을 발견하고 설치하며 평가 및 조직하는 방법을 다룹니다.
2026년 텍스트 음성 변환(TTS) 기술이 빠르게 발전했습니다. 이 가이드는 상업용 및 오픈 소스 TTS 모델을 품질, 지연 시간, 비용, 언어 지원 및 라이센스 기준으로 비교하여 엔지니어들이 적합한 모델을 선택할 수 있도록 돕습니다.

제네시스 AI가 2026년 5월 27일 물리, 렌더링, 컴파일, 도구를 포함한 시뮬레이션 플랫폼 ‘제네시스 월드 1.0’을 출시했습니다. 이 시스템은 시뮬레이션과 실제 로봇 성능 간의 상관관계를 0.8996으로 달성했습니다.

헤르메스 에이전트가 MCP의 컨텍스트 부풀림 문제를 해결하기 위해 툴 검색 기능을 추가했습니다. 이 기능은 BM25 점진적 스키마 공개를 활용하여 정확도를 49%에서 74%까지 향상시킵니다.
AgentTrove는 170만 개의 에이전트 상호작용 트레이스를 포함한 오픈 소스 데이터셋입니다. 이 튜토리얼에서는 Python을 사용해 데이터셋을 스트리밍하고, 에이전트의 발화를 정규화하며, 명령어를 추출하는 방법을 설명합니다.

NVIDIA가 X-Token을 발표하며 GOLD의 두 가지 구조적 문제를 해결하고 GSM8k 정확도를 2.56에서 15.54로 향상시켰습니다.
StepFun이 198B MoE 모델인 Step 3.7 Flash를 출시했습니다. 이 모델은 네이티브 비전 기능과 256k 컨텍스트, 어드바이저 모드를 지원합니다.
UC 버클리의 UCCL 팀이 다중 GPU 및 노드를 지원하는 mKernel을 출시했습니다. 이 라이브러리는 NVLink와 RDMA를 통합하여 효율적인 GPU 기반 통신을 가능하게 합니다.

Hexo Labs가 MIT 라이센스 하에 자가 개선 루프인 SIA를 오픈소스로 공개했습니다. 이 에이전트는 각 실행의 경로를 읽고, 구조를 재작성하거나 LoRA 가중치를 업데이트합니다.
이 튜토리얼에서는 Google Colab 또는 리눅스 환경에서 완전한 Ansible 자동화 실습실을 구축하는 방법을 소개합니다. Ansible 설치부터 인벤토리 설정까지 다양한 개념을 다룹니다.

Liquid AI가 8.3B 매개변수 중 1.5B를 활성화한 LFM2.5-8B-A1B 모델을 출시했습니다. 이 모델은 소비자 하드웨어에서 128K의 컨텍스트, 추론 및 도구 호출 기능을 제공합니다.
앤트로픽이 클로드 오퍼스 4.8을 출시하며 동적 워크플로우와 저렴한 빠른 모드를 도입했습니다. 현재 연구 미리보기 단계에 있습니다.
Perplexity AI가 재작성한 유니그램 토크나이저를 오픈 소스로 공개했습니다. 이 토크나이저는 재랭커의 지연 시간을 줄이고 CPU 사용량을 5-6배 감소시킵니다.
이 튜토리얼에서는 Google Colab에서 pgvector를 활용한 벡터 데이터베이스를 구축하고 PostgreSQL의 기능을 탐구합니다. PostgreSQL 설치부터 pgvector 확장 컴파일, Python 통합까지의 과정을 다룹니다.

사카나 AI가 제안한 DiffusionBlocks는 잔여 네트워크를 독립적으로 학습할 수 있는 블록으로 변환하는 훈련 프레임워크입니다. 이 방법은 레이어 업데이트를 역 확산 잡음 제거 단계로 해석합니다.

NVIDIA가 언어 에이전트를 훈련하기 위한 새로운 롤아웃 프레임워크 ‘Polar’를 발표했습니다. 이 프레임워크는 에이전트 하네스를 수정하지 않고도 강화 학습을 통해 훈련할 수 있도록 설계되었습니다.

EAGLE 팀과 vLLM, TorchSpec이 협력하여 EAGLE 3.1을 출시했습니다. 이 알고리즘은 생산 환경에서 발생하는 추측적 디코딩의 불안정성을 해결합니다.

NUS, MIT, A*STAR의 연구진이 LLM 파라미터를 수정하지 않고 새로운 지식을 훈련할 수 있는 MEMO라는 모듈형 프레임워크를 제안했다.
이 튜토리얼에서는 제로엔트로피의 제랑크-2 리랭커를 사용하여 검색 품질을 향상시키는 방법을 소개합니다. 기본적인 쿼리-문서 쌍 점수 매기기에서 실용적인 두 단계의 검색 및 재랭크 파이프라인으로 발전하는 과정을 다룹니다.

스테이블 AI가 악기 음악과 음향 효과 생성을 위한 스테이블 오디오 3를 출시했습니다. 이 모델은 소형 및 중형 변종의 오픈 가중치를 포함하고 있습니다.
OmniVoice Studio는 음성 클로닝, 비디오 더빙, 실시간 받아쓰기 및 화자 구분 기능을 제공하는 오픈소스 소프트웨어입니다. 클라우드 계정이나 구독 없이 개인 하드웨어에서 실행됩니다.
이 튜토리얼에서는 Open-MM-RL 데이터셋을 기반으로 멀티모달 추론 및 강화 학습을 위한 RLVR 파이프라인을 설계하는 방법을 다룹니다. 데이터셋을 로드하고, 스키마를 검사하며, 다양한 도메인과 형식을 분석합니다.

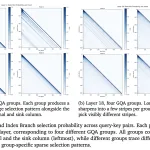
Together AI가 OSCAR(오프라인 스펙트럴 공분산 인식 회전)를 공개했습니다. 이 시스템은 긴 문맥의 LLM 서비스를 위한 INT2 KV 캐시 양자화 방법으로, 메모리 사용량을 약 8배 줄이고 디코드 속도를 최대 3배 향상시킵니다.
이 튜토리얼에서는 NVIDIA FLARE를 사용하여 비대칭 CIFAR-10 환경에서 FedAvg와 FedProx를 비교하는 연합 학습 실험을 진행합니다. 클라이언트 데이터는 디리클레 분포를 사용해 불균형한 레이블을 시뮬레이션합니다.