
데이터 선택을 위한 샘플 유틸리티 평가: 모델 가중치 모방
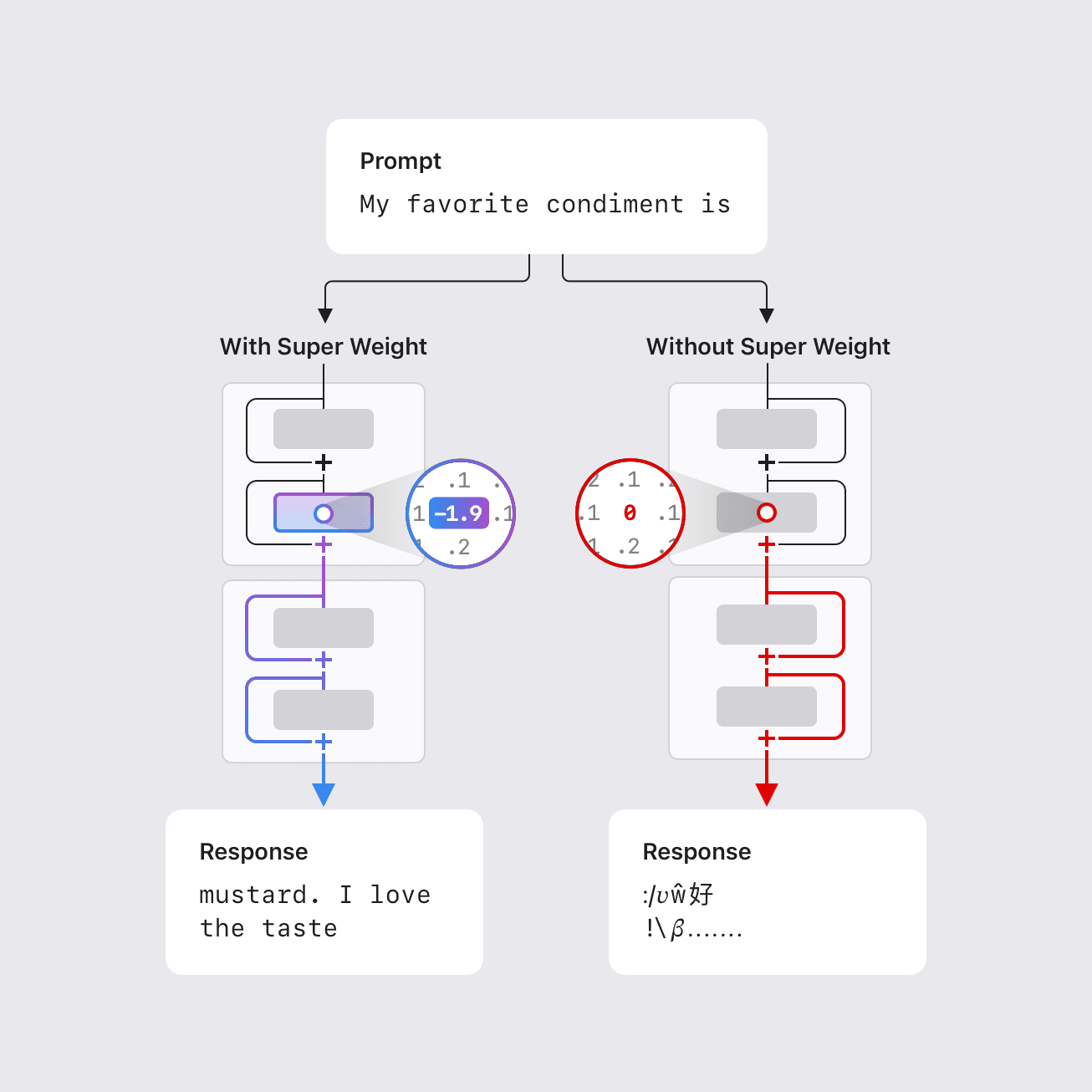
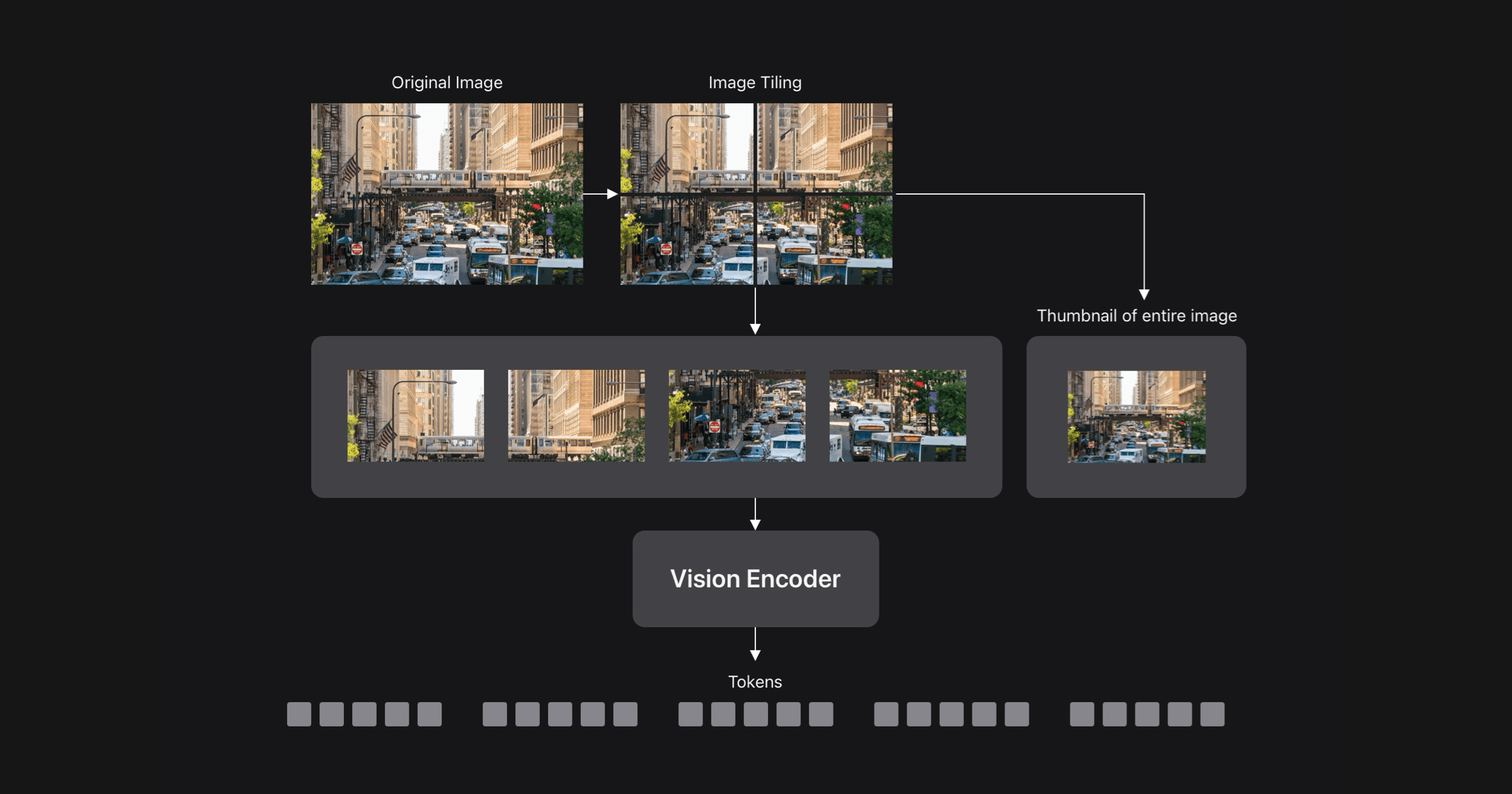
노이즈, 편향, 불필요한 정보를 포함하는 대규모 웹 크롤링 데이터셋에서 다중 모달 모델을 훈련시키는데 데이터 선택 기술의 중요성. 모델 무관한 방법과 모델 기반 방법을 비교하며, 후자는 계산적으로 부담스러울 수 있음. 이 연구에서는 모델 가중치를 모방하여 데이터 선택 방법을 제안한다.